The Security Stack I'd Build From Scratch in 2026
I’m Brian Olson, a cybersecurity professional with deep experience in DFIR and network forensics—currently working in Big Tech. My mission? To share hard-won lessons not just with fellow experts, but with anyone learning and growing in security—especially those in smaller companies without the resources or teams a massive enterprise has. I started blogging to break down real-world strategies, honest tool reviews, and battle-tested workflows in plain language. Whether you’re an underdog SOC analyst or a curious IT pro tackling security for the first time, my goal is to make the practical side of cybersecurity a little less overwhelming—and a lot more actionable. Expect guides that cut through the noise, resources that are actually useful at the keyboard, and stories that prove you don’t need a giant budget to make a real impact. You’ll also find my takes on personal finance, real estate, and anything that helps us level up—in and out of work. Let’s connect. We’re all in this together!
I need to be upfront about something before we get into this: I have tried to self-host my own infrastructure more times than I can count. And every single time, I've eventually gone back to SaaS.
Not because I don't know what to build. Not because I lack the skills. I've spent eighteen years in DFIR and security engineering. Intelligence community, top-tier IR firms, Fortune 500s. I've seen some things. I teach forensics at SANS. I can architect a defense-in-depth stack in my sleep. The problem has never been the what. It's always been the keeping it running.
Something breaks on a Tuesday night while you're in some random city teaching a class or on vacation with your family. A container update conflicts with another service. A disk fills up because I forgot to set up log rotation on that one thing. A certificate renewal fails silently and I don't notice for three days. Each time, I tell myself I'll build better automation or better monitoring. And each time, the maintenance overhead slowly wins the war of attrition until I'm back on Google Workspace and 1password and telling myself "at least it just works."
So this post is a bit of a contradiction. It's the security stack I would build from scratch in 2026, written by someone who has repeatedly failed to keep that stack alive long-term. I think that tension is actually the most honest and useful thing I can share. Because if you're reading this and nodding along, you're probably in the same boat.
The architecture isn't the hard part. It never was.
The Design Principles
Every tool in this stack earns its place by satisfying at least two of three criteria:
It reduces my attack surface, not just monitors it. It operates with minimal ongoing maintenance (because a security tool you stop updating is worse than no tool at all). Or it gives me visibility I wouldn't otherwise have.
If a tool only does one of these things, it needs to be exceptional at it. If it does none, it's bloat.
The other principle I hold sacred: every layer assumes the layer above it has already been compromised. My firewall rules assume my reverse proxy is owned. My application authentication assumes my network perimeter is breached. My encryption assumes my filesystem is exposed. That's not paranoia. It's how I've watched real breaches propagate for nearly two decades.
And the third principle, the one I've learned the hard way: if you can't maintain it, it will eventually become a liability instead of an asset. I'll come back to this.
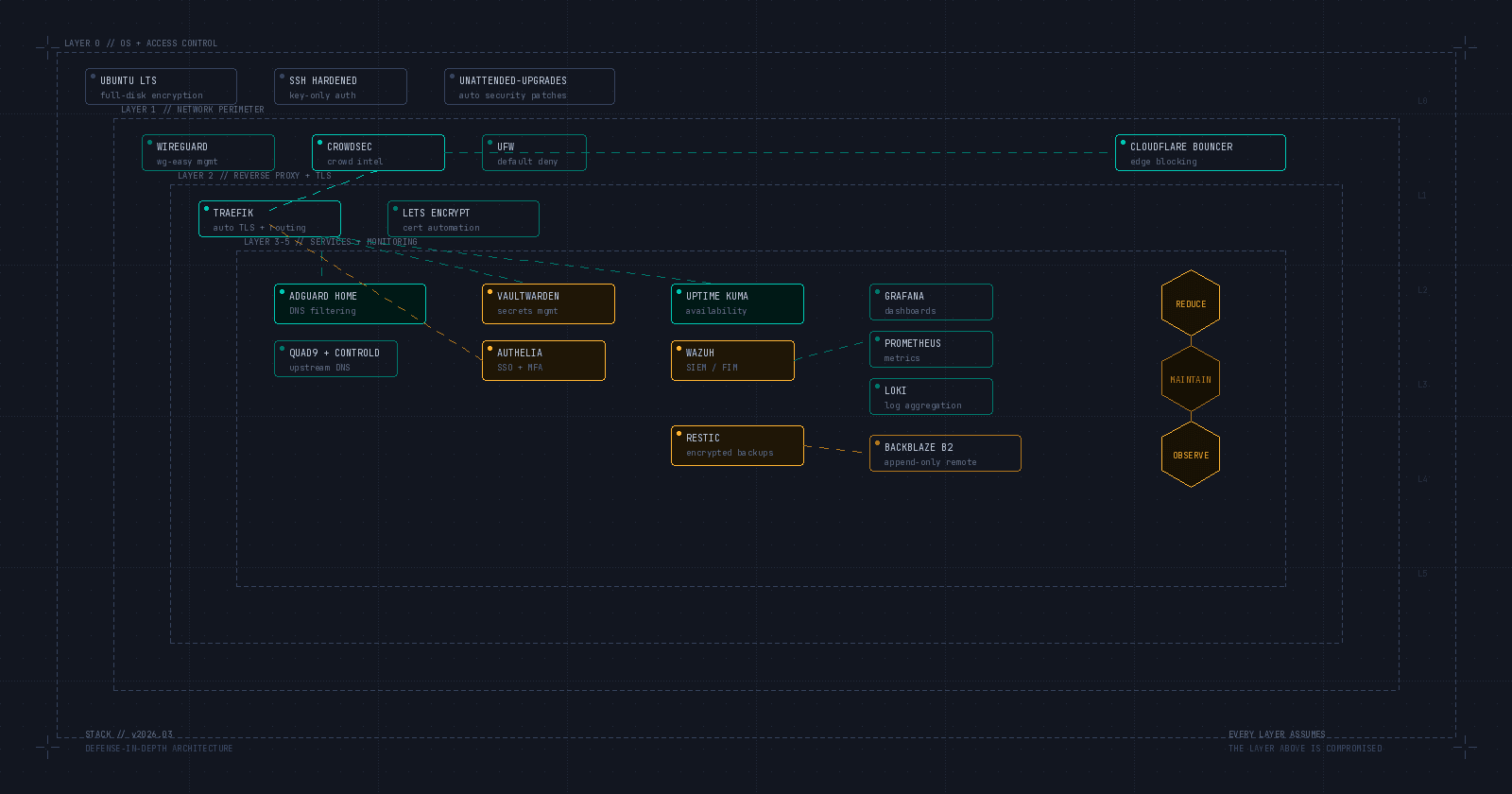
Layer 0: OS and Access Control
Everything starts here, and most people get it wrong by overthinking it.
Ubuntu Server LTS on a reputable VPS provider with full-disk encryption. I know the Debian purists will come for me, but Ubuntu's update cadence, LTS support windows, and ecosystem breadth make it the pragmatic choice for a stack you need to maintain, not just deploy.
SSH hardened properly. Key-only authentication, non-standard port (yes, it's security through obscurity, and yes, it still eliminates 99% of automated scanning noise), and AllowUsers restricted to named accounts. No root login. Ever. If you're still using password-based SSH authentication in 2026, we need to have a different conversation.
Unattended-upgrades enabled for security patches. I've seen too many self-hosted setups where the operator deployed a beautiful stack and then never patched it again. Automatic security updates aren't optional. They're table stakes. This is also, honestly, one of the few parts of the stack that actually takes care of itself once you set it up. Treasure that.
Layer 1: Network Perimeter
Tailscale for remote access. I've written about why commercial VPNs are a problem, and Tailscale is the answer I landed on. It's built on WireGuard under the hood, so you get the small codebase and fast handshakes, but wrapped in a mesh networking layer that handles key management, NAT traversal, and device auth without you having to think about it. No port forwarding. No manual config files. No fiddling with peer connections when you should be sleeping. It just works, which as you've gathered by now is the thing I value most.
CrowdSec as the first active defense layer. This is where I'd part ways with a lot of self-hosting guides that still recommend Fail2Ban. Look, Fail2Ban is a fine tool that served the community well for two decades, and I'm not here to trash it. But it's fundamentally reactive and isolated. Your Fail2Ban instance only knows about attacks it has personally witnessed.
CrowdSec operates on the same log-parsing principles but adds two capabilities that change the calculus. First, crowd-sourced threat intelligence: your instance benefits from attacks seen across the entire CrowdSec network, so you can block known-bad IPs before they ever knock on your door. Second, a distributed architecture where detection and remediation can be split across machines. For a single-server setup the crowd intelligence alone justifies the switch.
Pair it with the CrowdSec firewall bouncer for nftables-level blocking and, if you're using Cloudflare, the Cloudflare bouncer to push blocks to the edge before traffic even reaches your server.
UFW with a default-deny posture. Only the ports you explicitly need are open. I'm amazed how many self-hosted setups I've reviewed where Docker's default behavior of bypassing UFW rules wasn't accounted for. If you're running Docker, you need to set DOCKER_IPTABLES=false or use Docker's --iptables=false flag and manually manage your port exposure. This is one of the most common misconfigurations I see.
Layer 2: Reverse Proxy and TLS
Traefik as the reverse proxy and automatic TLS termination point. I've used Nginx Proxy Manager, Caddy, and raw Nginx configs over the years across various attempts at this. Traefik wins for Docker-native environments because it discovers services via container labels. No manual config file editing when you add or remove services. Automatic Let's Encrypt certificate provisioning and renewal. Middleware chains for rate limiting, IP whitelisting, and header manipulation.
One critical detail: every service behind Traefik gets its own subdomain, and nothing is exposed on a path prefix. vault.yourdomain.com, not yourdomain.com/vault. This gives you per-service TLS certificates, cleaner access control, and easier log analysis. It also makes life significantly simpler when you want to lock down or move an individual service later.
Traefik is also, I should note, one of the things that has gotten dramatically easier since my earlier attempts. The v2/v3 config model with Docker labels is night and day compared to where this ecosystem was three or four years ago.
Layer 3: DNS
AdGuard Home for DNS-level filtering and visibility. Pi-hole is the more famous choice, but AdGuard Home has native DNS-over-HTTPS and DNS-over-TLS support, a cleaner interface, and better handling of encrypted DNS clients. More importantly for our purposes, it gives you a DNS query log that is incredibly useful for security monitoring. You'd be surprised how much you can learn about what's happening on your network just by watching DNS queries.
Upstream resolvers pointed at ControlD, which I've written about in detail. It blocks known-malicious domains at the resolver level, supports category-based filtering for blocking entire classes of risky domains without maintaining manual blocklists, and gives you granular per-device policies if you want them. Another layer of protection that costs almost nothing to maintain once it's configured.
Layer 4: Secrets and Identity
This is the layer most self-hosters skip, and it's the layer that matters most.
Vaultwarden for password management. It's a community-built Rust implementation of the Bitwarden server that's fully compatible with all official Bitwarden clients. The official Bitwarden server requires 2+ GB of RAM and runs multiple heavy services. Vaultwarden does the same job in about 128 MB. For a self-hosted stack where resources matter, this is a no-brainer. Put it behind Traefik with its own subdomain, enforce HTTPS-only, and disable open registration immediately after creating your account.
I'll also say this: Vaultwarden is one of the services I've come closest to keeping self-hosted permanently. It's stable, it's lightweight, and the Bitwarden clients are excellent. If I were going to self-host exactly one thing and leave everything else on SaaS, this might be it.
Authelia for single sign-on and multi-factor authentication across all services. Without centralized authentication, every service is its own identity silo with its own password, its own session management, and its own attack surface. Authelia sits in front of Traefik as a forward-auth middleware and gives you TOTP-based MFA, WebAuthn/FIDO2 support, and granular access policies per subdomain. One login, one MFA challenge, access to everything you're authorized for.
If you're running five or more services (and you will be), Authelia is the single biggest quality-of-life and security improvement you can make.
Layer 5: Monitoring and Visibility
You can't defend what you can't see.
Uptime Kuma for service availability monitoring. Lightweight, self-hosted, and genuinely beautiful. It monitors HTTP endpoints, TCP ports, DNS resolution, and Docker containers. Push notifications to your phone when something goes down. I mentioned this in my self-hosting post as a five-minute deploy, and I stand by that.
Wazuh for security event monitoring if you want a full SIEM experience. I'll be honest: Wazuh is the heaviest component in this stack and the one most likely to feel like overkill for a personal setup. But if you're running services that handle real data for real people, having file integrity monitoring, log aggregation, and vulnerability detection in one platform is worth the resource cost.
For those who want visibility without the SIEM weight, Grafana + Prometheus + node_exporter gives you system-level metrics, and Loki handles centralized log aggregation. Lighter footprint, less out-of-the-box security context, but still infinitely better than SSH-ing into your box and tailing log files every time something feels off.
Layer 6: Backups
The layer everyone forgets until it's too late.
Restic for encrypted, deduplicated backups to an off-site destination. I back up to Cloudflare R2 with append-only credentials so that even if my server is fully compromised, the attacker can't delete my backup history. R2 also has zero egress fees, which matters a lot more than you think until the day you actually need to restore.
The strategy is simple: daily automated backups of all Docker volumes, all configuration files, and the host's /etc directory. Retention: 7 daily, 4 weekly, 6 monthly. And I test restores quarterly. A backup you've never restored from is a hypothesis, not a strategy.
What I Intentionally Left Out
No Kubernetes. No Ansible playbooks. No Terraform modules. Not because these tools aren't valuable (they absolutely are in the right context), but because for a single-server or small-cluster self-hosted stack, they add complexity that doesn't pay for itself. Every layer of abstraction is a layer you have to understand when something breaks in the middle of the night.
I also didn't include a WAF. For a self-hosted stack where you control every application behind the reverse proxy, a well-configured Traefik instance with rate limiting and CrowdSec integration gives you most of what a traditional WAF provides without the tuning overhead. If you're exposing third-party applications with known vulnerability patterns, revisit this decision. But for this stack? The juice isn't worth the squeeze.
The Part Nobody Talks About
Here's where I stop being the architect and start being honest.
I can deploy everything above in a weekend. I've done it. Multiple times. And with Claude you can knock this out in less than an hour. The initial setup is almost the fun part. You're in the zone, containers are coming up, Traefik is issuing certs, Uptime Kuma is lighting up green across the board. It feels great.
Then week three happens. Or month two. You get busy at work. A container update introduces a breaking change and you don't have time to debug it that night. Your monitoring alerts you about a disk usage warning but you snooze it because you're in the middle of something. Slowly, the entropy accumulates. Services start drifting. You're not sure which compose files match what's actually running. And one day you realize you've spent your Saturday morning doing ops work instead of literally anything else, and you ask yourself why you're not just paying $20/month for someone else to deal with this.
I know this cycle intimately because I've lived it over and over. The "awesome self-hosted" lists never tell you about this part. They show you the architecture diagram and the docker-compose up -d and then leave you alone with the ongoing reality of actually operating infrastructure.
I spend roughly 30 minutes per week when things are going well. But things don't always go well, and the spikes are what kill you. A single bad update can eat an entire evening. And if you let maintenance slide for a few weeks, the catch-up cost grows nonlinearly.
That's the real cost of self-hosting. Not the hardware, not the bandwidth, not the initial setup. It's the ongoing commitment to actually maintaining what you built. If you're not willing to make that commitment, a well-chosen SaaS provider with strong security practices is genuinely the better choice. I said the same thing in my self-hosting post and I mean it more now than when I wrote it, because I'm the living example.
So Why Write This Post?
Because I keep coming back. That's the part that won't let me go. Every time I retreat to SaaS, I last about six months before the privacy itch starts again, or I read about another breach, or I see my credit card statement and do the math on what I'm paying for services I could run myself. And I start spinning up containers again.
Everything I wrote in Why Self-Hosting Matters is still true. The reasons haven't changed. I haven't changed. I just keep hoping that this time I'll figure out how to make it stick.
Maybe writing it down helps. Maybe if I'm more deliberate about the stack choices upfront, more realistic about the maintenance budget, more disciplined about not over-scoping on day one, the outcome will be different. Or maybe I'll be back on Gmail by August. I honestly don't know.
But I do know the architecture above is sound. And if you're someone who's been through this same cycle, at least you know you're not alone.
Am I the only one stuck in this loop? I'd genuinely love to hear from people who've made self-hosting stick long-term. What's your secret? Because I clearly haven't figured it out yet. Drop a comment.